Wstęp
W ramach naszego koła naukowego czasami organizujemy całoroczne hackathony. Nasi członkowie zbierają się w grupy i przygotowują aplikacje, które konkurują o tytuł najlepszej. Aplikacja, LARKFiD powstała właśnie na takim hackathonie.
Naszym celem, jako grupy uczestniczącej w Hackathonie, było stworzenie aplikacji, która zbiera, deduplikuje, przetwarza i umożliwia dostęp do informacji z regionu tj. województwa podkarpackiego.
Zbieranie danych polega na przeszukiwaniu stron internetowych, forów i grup dyskusyjnych z regionu w poszukiwaniu informacji. Przykładami takich informacji mogą być: ogłoszenia o zaginionych psach, dzikach chodzących po ulicach, utrudnienia na drogach — dosłownie wszystko.
Deduplikacja danych to krok, który ma połączyć/usunąć te same informacje, pochodzące z różnych źródeł np. z dwóch portali piszących o tym samym wydarzeniu.
Tak zebrane informacje powinny być przetworzone do wspólnej postaci zawierającej np. datę i miejsce wydarzenia (fakty) oraz przedstawione w postaci łatwej w do przyswojenia np. w postaci skrótów wiadomości i pinesek na mapie.
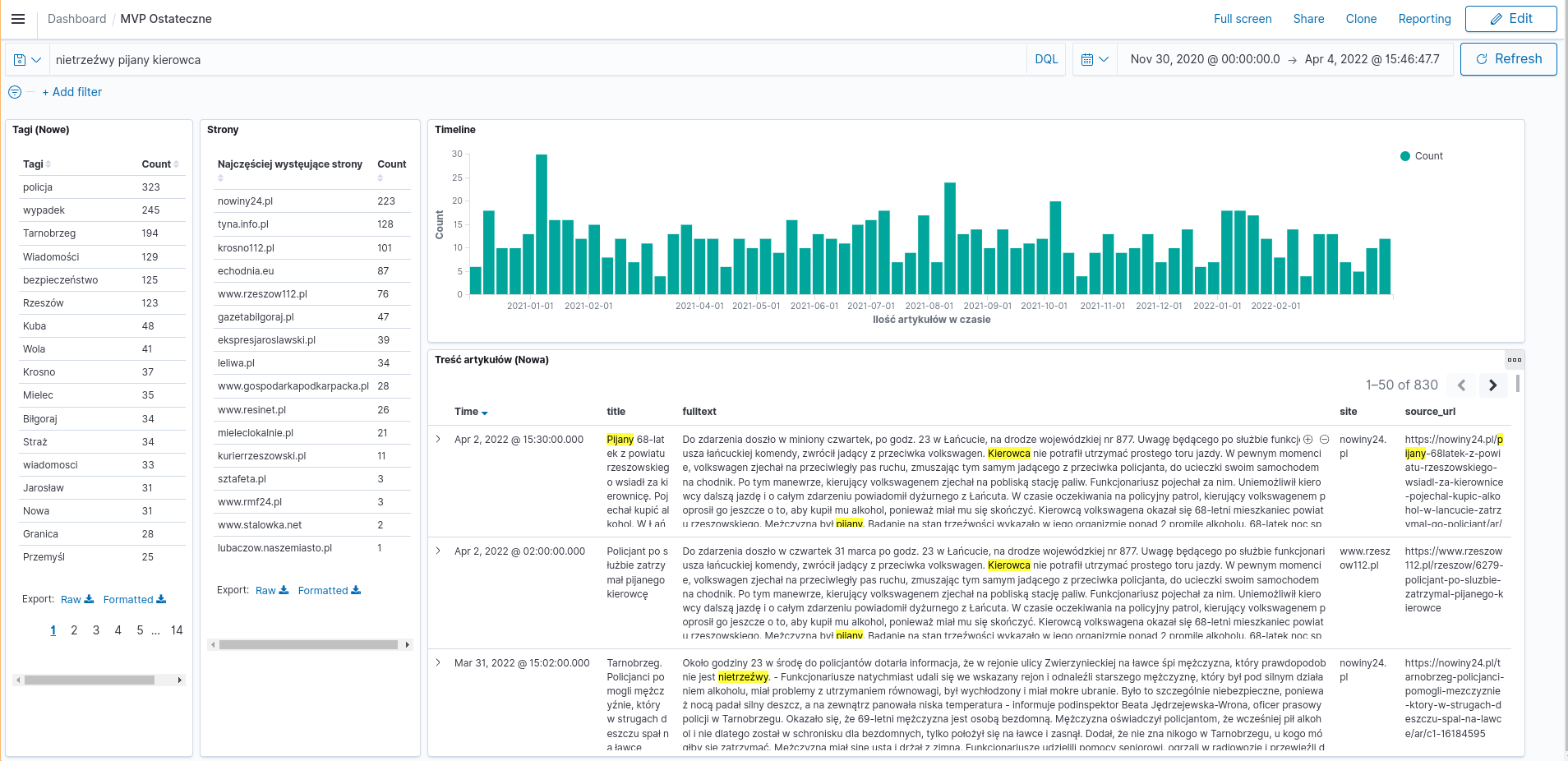
Interfejs użytkownika
Oto interfejs użytkownika, który został stworzony w ramach projektu. Poniżej zamieszczone zostały opisy funkcji wraz ze zdjęciami je prezentującymi.
W polu “wyszukaj” wpisać można frazę, według której odfiltrowane będą artykuły, zaktualizuje się widok stron, ich treść i oś czasu.
Dobór technologii i metod
Zbieranie danych
Zbieranie danych to klasyczny problem web scrapingu. Do ich zebrania można zaprogramować “pająki” chodzące po wskazanych stronach i pobierające artykuły lub posty na forum/grupach. Technologie, które można by do tego wykorzystać to np. RSS, Python (Scrapy).
Ekstrakcja informacji (faktów)
Każdy artykuł/post/wpis to tylko tekst ze zdjęciami, nie zawiera on metadanych o miejscu/wydarzeniu, które można odczytać. Aby to zrobić, trzeba przetworzyć pobrany tekst w poszukiwaniu dat, nazw miejsc, osób i nazwisk. Do tego zadania można wykorzystać np. Morfeusza 2 (dla języka polskiego), modele LLM (ChatGPT, LLaMA), i techniki NLP — Entity recognition.
Morfeusz 2 to narzędzie do analizy morfologicznej języka polskiego. Pozwala ono na podział tekstu na wyrazy, a następnie na analizę morfologiczną tych wyrazów. Dzięki temu można np. wyodrębnić nazwy miejsc, osób i nazwisk.
Modele LLM to modele językowe, które można wykorzystać do generowania tekstu. W tym przypadku można wykorzystać je do wygenerowania krótkiego podsumowania artykułu.
Deduplikacja
Deduplikacja to jest jeden z trudniejszych problemów, bo dla każdego z artykułów należy zdecydować, czy artykuł o tym samym temacie/treści nie znajduje się już w bazie. Żeby to zrobić, można porównać:
- Tytuły — czy są identyczne/przekazują tę samą informację różnymi słowami?
- Treści — identycznie jak Tytuły.
- Datę publikacji — bliska data publikacji sugeruje pewien związek (a nawet powielenie)
- Lokalizację wydarzenia (jeżeli występuje)
- Inne powiązania, wynikające np. z bliskości źródeł np. strona www i fb tej samej firmy.
Technologie: Python (NLP: Text similarity, Semantic Textual Similarity), Mozilla Readablility, Morfeusz 2.
Implementacja
Nie będę ukrywać, że po pierwsze nie mieliśmy doświadczenia w tworzeniu tego typu aplikacji, a po drugie: zbyt wcześnie myśleliśmy o skali, o tym, jak wiele wiadomości możemy przetworzyć i jak zaprojektować system tak by najpierw działał. Więc to, co stworzyliśmy, było zdecydowanie zbyt skomplikowane. Natomiast pozwoliło nam “pobawić” się wieloma ciekawymi technologiami i napotkać problemy, których inaczej napotkać się nie da. Była to dla nas wszystkich cenna lekcja.
To, że architekturę aplikacji tworzą małe serwisy (które można by nazwać mikro), wcale nie oznacza, że architekturą tej aplikacji są mikroserwisy. Wręcz przeciwnie, architektura LARKFiD to monolit, gdyż zależności między kolejnymi serwisami są bardzo duże (wszystkie serwisy tworzą jeden potok danych).
Jej podstawą jest message broker — RabbitMQ. Jego zadaniem jest przekazywanie wiadomości między serwisami. Pierwszą częścią architektury jest “scheduler” i “rss-downloader”, odpowiadają one za pobieranie danych z feedów RSS i indeksowanie linków do artykułów w nich zawartych.
Następnym krokiem jest wydanie zadania do zindeksowania danego artykułu (z wcześniej zindeksowanego linku), zadanie to wykonuje “Article downloader”. Po pobraniu artykułu dodatkowo wydobywa on z niego treść przy wykorzystaniu Readability od Mozilli.
Ostatnim krokiem jest utworzenie wektorów z wydobytych tekstów (embeddings), które posłużą później do wykonywania zapytań przy wykorzystaniu języka naturalnego. Silnikiem tych zapytań jest OpenSearch KNN Plugin. Artykuł na ten temat stworzyłem tu 1. Oto przykładowa interakcja z wyszukiwaniem z wykorzystaniem kNN:
Query: healthy breakfast
[{'_id': 'WigKpoIBm1k5Fu0Qp171',
'_index': 'recipes',
'_score': 0.8946137,
'fields': {'description': ['a healthy breakfast option'],
'id': [259963],
'name': ['spinach toast']}},
{'_id': 'biUApoIBm1k5Fu0Qu3bT',
'_index': 'recipes',
'_score': 0.85431683,
'fields': {'description': ['yummy healthy breakfast'],
'id': [156942],
'name': ['apple pancake bake']}}]
Dodatkowo poprzez serwis OpenSearch Dashboards użytkownik ma możliwość bezpośredniego przeszukiwania bazy danych.
Obecna implementacja projektu nie dokonuje deduplikacji, ekstrakcji faktów i przetwarzania ich do postaci łatwej do przyswojenia.
Podsumowanie i wnioski
Niestety, projekt ten nie został ukończony, głównie ze względu na brak zasobów ludzkich. Jednak jeżeli jesteś członkiem koła i zainteresował Cię ten projekt napisz do @finloop na Discordzie koła.
Plan jest taki, aby w przyszłości kontynuować ten projekt i skupić się na:
- Nieindeksowanych przez przeglądarki danych np. z grup na Facebooku, Instagrama I Tiktoka. Ciekawy artykuł jak to robić znalazłem tu 2.
- Agregacji danych pochodzących z różnych źródeł.
- Wyciąganiu z tych danych informacji o wydarzeniu, lokalizacji, czasie i tworzeniu podsumowań.
- Przetwarzaniu tych informacji do postaci łatwej do przyswojenia.
Priorytetem byłoby MVP, prosta aplikacja, z której można przeglądać dane.
Projekt ten przygotowano w ramach realizacji projektu pt.: „Hackathon Open Gov Data oraz stworzenie innowacyjnych aplikacji, z wykorzystaniem technologii GPU”, dofinansowanego przez Ministra Edukacji i Nauki ze środków z budżetu państwa w ramach programu „Studenckie koła naukowe tworzą innowacje”.